AIの活用方法を知る
AIの基礎的な知識からビジネスにおけるAI活用事例まで
AIのプロジェクトを始める際に役立つ情報をお届けします。
AIの基礎的な知識からビジネスにおけるAI活用事例まで
AIのプロジェクトを始める際に役立つ情報をお届けします。
人工知能(AI)とは「Artificial Intelligence」の略で、学習や推論、判断等の人間の知能のもつ機能を備えたコンピューターシステムなどと呼ばれています。しかし、学術的な視点では「AI」という言葉は多義的であり、人によってその捉え方は異なります。AIの定義は、専門家の間でも明確に定まっていないのが現状です。
AIはいくつかの種類に大別できます。
たとえば、「人間のように考えるコンピューター」と「人間の能力の一部を代替するシステム」では、どちらもAIと定義されますが、持っている機能はまったく異なります。
具体的には「特化型AI」と「汎用型AI」、「強いAI」と「弱いAI」に分類して考えることができます。
そもそも、AIが人間のような知能を持つコンピューターであれば、汎用型AIこそが真のAIであり、特化型AIは課題解決を自動化する機械に過ぎない、という考え方もあります。
加えて、アメリカの哲学者であるジョン・サール氏が提唱した「強いAI」と「弱いAI」という分類もあります。
「特化型AI」と「汎用型AI」は「人間のように広範な課題を処理できるか」といった「課題処理」の視点で分類した概念です。一方で、「強いAI」と「弱いAI」は、「人工知能が人間の意識や知性を持つかどうか」という観点で分類した概念です。
つまり、「強いAI」と「弱いAI」、「汎用型AI」と「特化型AI」の関係性は、どのような観点でAIを判断するかの違いから分類されています。「強いAI」と「汎用型AI」、「弱いAI」と「特化型AI」は観点が異なる近い概念といえます。

今となってはさまざまな領域で認知されているAIですが、これまで「ブーム」と「冬の時代」を繰り返してきました。
「AI」という言葉が誕生したのは1956年にさかのぼります。当時、ダートマス大学の数学の教授であったジョン・マッカーシーが「人間のように考える機械」を「AI」と名付けました。
最初のブーム(第1次AIブーム)は、1950年代後半〜1960年代に勃興。この時代は「推論※2」や「探索※3」と呼ばれる技術により、パズルや簡単なゲームなど、明確なルールが存在する問題に対して高い性能を発揮し、AIに大きな期待がかけられました。しかし、現実の複雑な問題は解けないという性能的な限界が見えると、ブームは下火となります。
このときAIが解けた実用的でない問題は「おもちゃの問題(トイ・プロブレム)」と呼ばれました。
(※2)人間の思考過程を、記号で表現し実行しようとすることを指します。
(※3)目的となる条件(答え)を、解き方のパターンを場合分けして探し出すことを指します。
次のブーム(第二次AIブーム)が起こったのは1980年代。この時代は、AIに専門家のように「知識」をルールとして教え込み、問題解決させようとする「エキスパートシステム」の研究が進展します。
エキスパートシステムの研究が進むことで、「医療診断」などビジネスへの応用例も現れるようになりました。しかし、人間の持つ「一般常識」レベルの膨大な知識を記述しなければならないことや、例外処理、矛盾したルールに対応できないといった壁に直面し、ブームは再び終息に向かいます。
2000年代からまさに現在にかけて、第3次AIブームを迎えます。
第三次AIブームの原動力になっているのが「ディープラーニング(深層学習)」という技術です。従来の機械学習(後の章で詳しく解説)では人間が特徴量※4を定義し、予測や推論の精度を上げていました。ディープラーニングを活用することで、学習データから自動で特徴量を抽出し、精度を向上させることが可能になりました。
「コンピューターが自ら特徴量を獲得する」ことは、AIの研究分野においてブレークスルーとなり、現在のAI研究のブームの起爆剤となりました。
(※4)機械学習における特徴量とは、学習の入力に使う測定可能な特性のことです。たとえば、赤いリンゴと青いリンゴを識別する際には、「色」が特徴量となります。人はものを識別する際に、無意識に適切な特徴量を利用しますが、ディープラーニングを除く従来の機械学習では、識別に利用すべき特徴量を人間が入力していました。これまで「人の顔の識別」などの複雑な問題において、AIに適切な特徴量を教えることが困難でした。
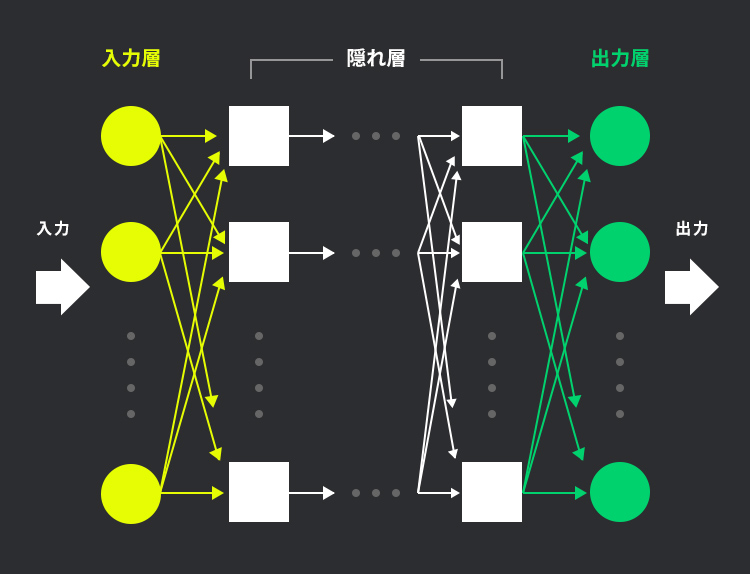
ディープラーニングとは、このニューラルネットワークの隠れ層を複数にすることで、特徴量をコンピューターが判断する手法です。
従来の機械学習とは異なり、学習に必要なデータさえ用意すれば学習に必要となる特徴量を自ら抽出できるため、従来、人の手で特徴量を与えていた機械学習では実現不可能だった、高性能な認識が可能になりました。
どの特徴量が重要なのかを自動的に学習できるようになり、人間が考えた特徴量を用いるよりも精度が高くなったと言われています。
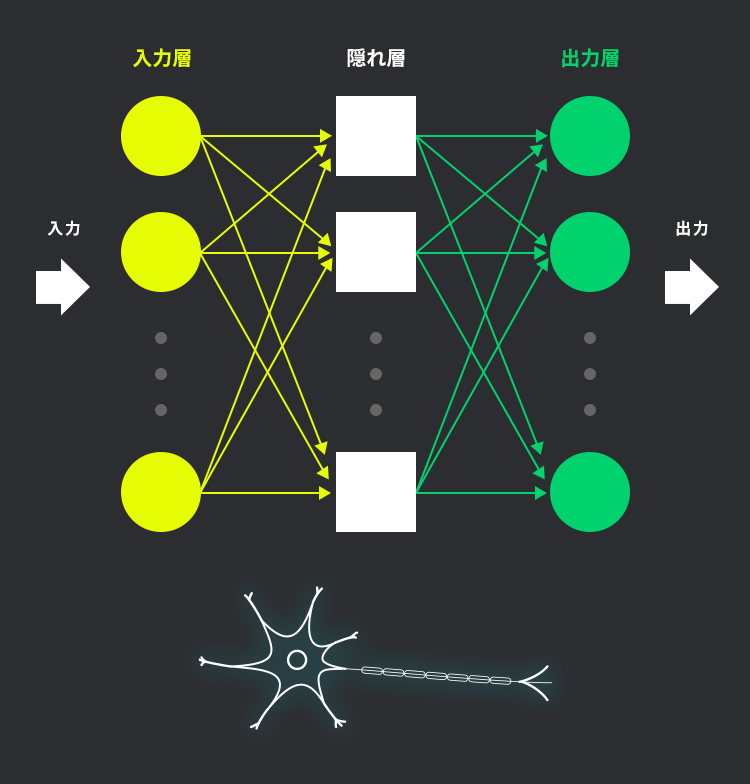
機械学習とは、コンピューターが大量のデータを学習し、分類や予測などのタスクを遂行するアルゴリズムやモデルを自動的に構築する技術です。現在使われているAIの中核技術と言っても過言ではありません。
機械学習の原型は第一次AIブームの1960年代から登場していますが、大量の学習データを処理するのに膨大な計算リソースが必要だったため、実用レベルに達するまでに時間がかかりました。2000年代以降にコンピューターの性能が向上し、2010年代からビッグデータを扱うようになり、膨大な計算リソースを獲得したことで実用化が進みました。
機械学習の手法は、主に教師あり学習、教師なし学習、強化学習の3種類に分けられます。機械学習の技術の1つに、第三次AIブームのきっかけとなったディープラーニングが存在します。

人間の脳を模したニューラルネットワークとは、データを入力する入力層、データを出力する出力層、入力層から流れてくる重みを処理する隠れ層から構成されます。
人間の脳を構成する神経細胞である「ニューロン」は、電気信号で情報を伝達します。情報伝達の速度は、ニューロンとニューロンの結合部分である「シナプス」の結合強度によって変わります。ニューラルネットワークでは、層と層の間にあるニューロン同士のつながりの強さを「重み付け」で表現します。
画像認識とは、人間の視覚機能と同じように静止画像や動画の内容を理解する技術です。
ディープラーニングが最初に適用された分野であり、現在では自動運転を実現するための中核技術として注目を集めています。ほかにも、工業製品の検査など製造業を中心に活用がされ、ロボットメーカーや自動車メーカーなどによる投資も盛んです。

音声認識とは、音声情報と言語情報を組み合わせることで、音声を文字に変換する技術です。
人間が言葉を脳で理解するのに対し、コンピューターはデータ化した音声の特徴量と、記号(音素や単語)を整合させることで音声を認識します。近年急速に普及したスマートフォンやAIスピーカーに搭載されているAIアシスタントの操作に不可欠な技術です。
ちなみに、音声認識は音声からテキストを生成する部分までの機能であり、テキストから意味を抽出し、目的に応じた作業を行う部分までは含まれず、この機能は「自然言語処理」が担っています。

自然言語処理とは、人間の言語(自然言語)を機械で処理する技術です。
具体的には、言葉や文章といったコミュニケーションで使う「話し言葉」から、論文のような「書き言葉」などの自然言語を対象とし、それらの言葉が持つ意味を解析する技術を指します。機械翻訳、カナ文字変換予想、AIアシスタントなどの音声対話システム、検索エンジンなどで活用されています。

予測とは、その名の通り将来を起こる事象をAIで予測する技術のことで、過去の膨大な量のデータを分析できます。
競馬のレースの着順予想やニュースから市場の変化予測、人口統計データとタクシー運行データなどからのタクシー乗車台数予測など、幅広く利用されています。
 AIとは
AIとは AIの身近な活用事例
AIの身近な活用事例 産業 × AI
産業 × AI あなたのビジネス × AI
あなたのビジネス × AI